Video Propagation Networks
Varun Jampani Raghudeep Gadde Peter V. Gehler
Abstract
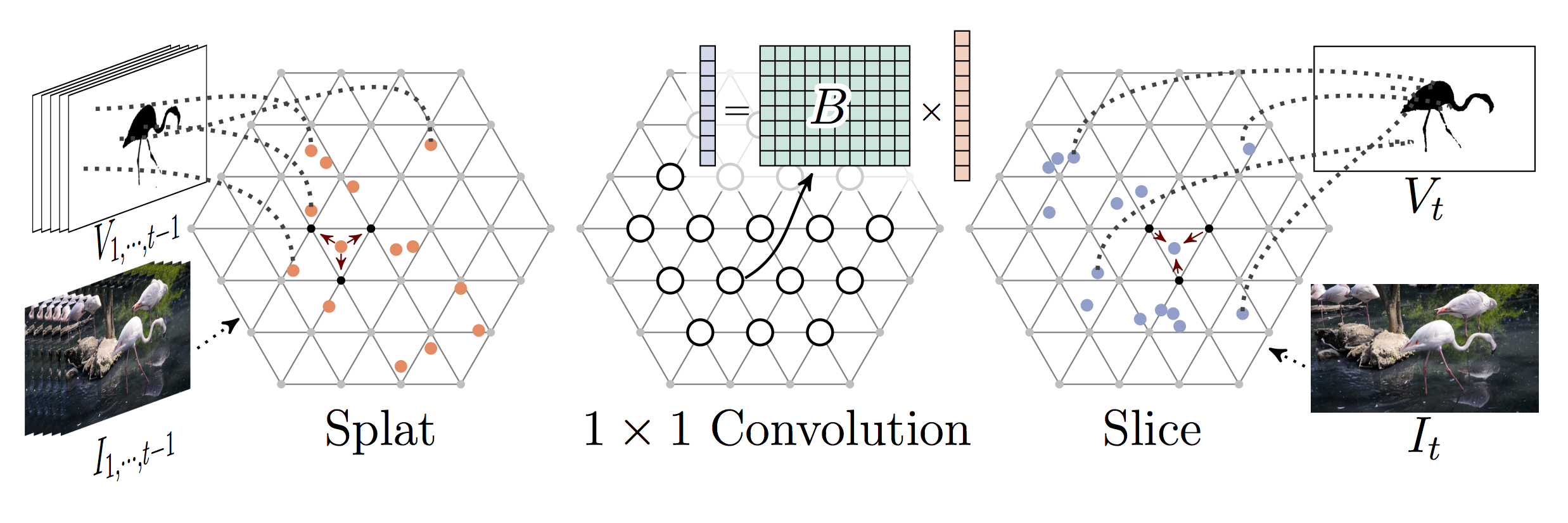
In this paper we propose a technique that propagates information forward through video data. The method is conceptually simple and can be applied to tasks that require the propagation of structured information, such as semantic labels, based on video content. We propose a ‘Video Propagation Network’ that processes video frames in an adaptive manner. The model is applied online: it propagates information forward without the need to access future frames other than the current ones. In particular, we combine two components, a temporal bilateral network for dense and video adaptive filtering, followed by a spatial network to refine features and increased flexibility. We present experiments on video object segmentation and semantic video segmentation and show increased performance comparing to the best previous task-specific methods, while having favorable runtime. Additionally we demonstrate our approach on an example regression task of propagating color in a grayscale video.
Paper
Please consider citing if you make use of this work and/or the corresponding code:
@inproceedings{jampani:vpn:2017,
title = {Video Propagation Networks},
author = {Jampani, Varun and Gadde, Raghudeep and Gehler, Peter V.},
booktitle = { IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
month = july,
year = {2017}
}
Code
We integrated video propagation network into Caffe neural network framework. Code is available in this github repository: https://github.com/varunjampani/video_prop_networks.
Usage
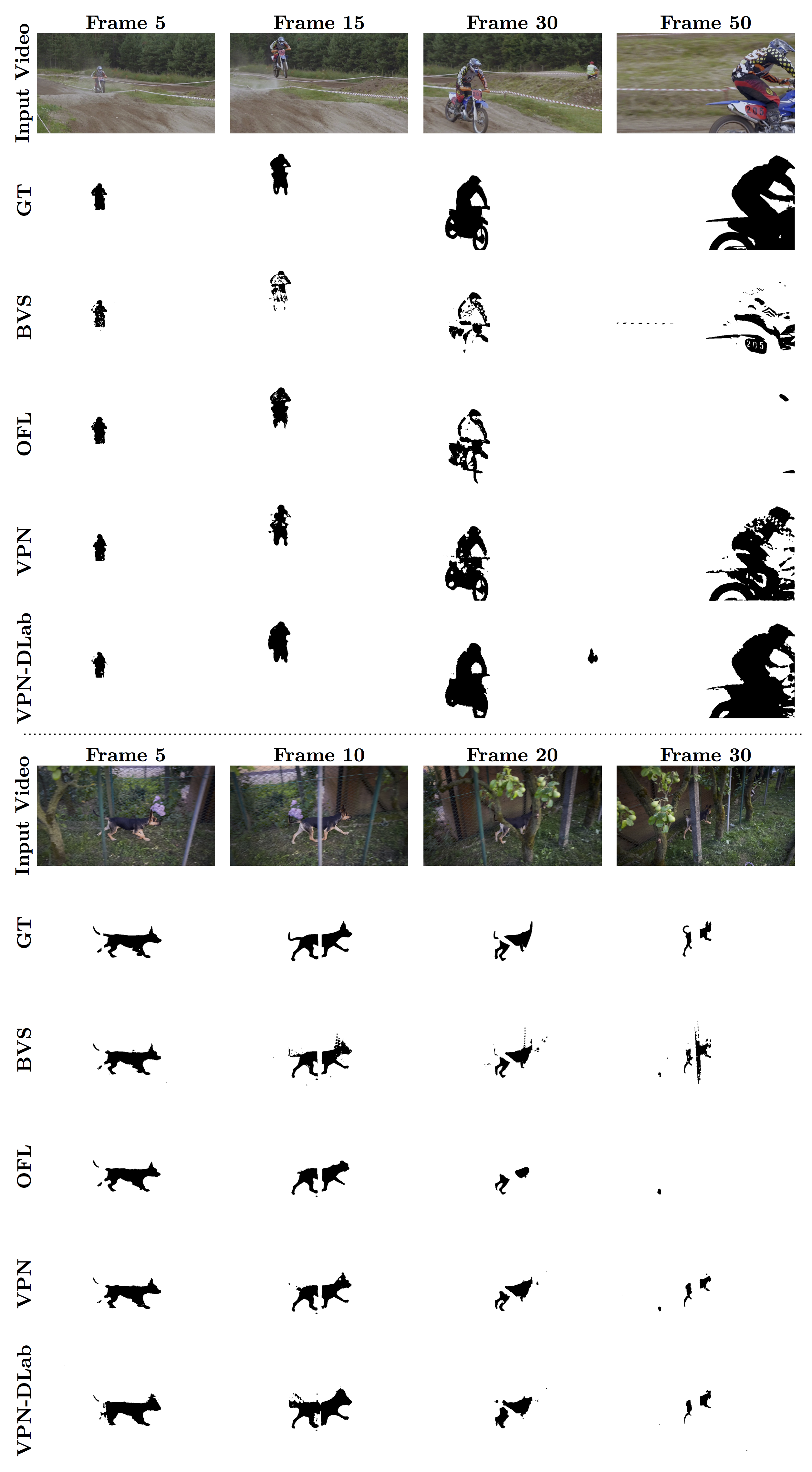
The video propagation networks are generic and can be used for propagating any type of information across video frames. They are end-to-end trainable and can be combined with any existing deep network. The main use of VPNs in comparison to standard spatio-temporal CNNs is that VPNs can enable long-range pixel/superpixel connections while being computationally fast. In this paper, we experimented with label propagation (foreground or semantic labels) and colour propagation. See experiments in the paper and the corresponding codes.
An example color propagation:

A couple of examples for object mask propagation: