Publications/Reports
Refer to my Google Scholar page for an up-to-date list of publications.
M. El. Banani, A. Raj, K. Maninis, A. Kar, Y. Li, M. Rubinstein, D. Sun, L. Guibas, J. Johnson, V. Jampani
Computer Vision and Pattern Recognition, CVPR’24
A. Engelhardt, A. Raj, M. Boss, Y. Zhang, A. Kar, Y. Li, D. Sun, R. M. Brualla, J. T. Barron, H. Lensch, V. Jampani
Computer Vision and Pattern Recognition, CVPR’24
G. Li, D. Sun, L. Sevilla-Lara, V. Jampani
Computer Vision and Pattern Recognition, CVPR’24
P. Sharma, V. Jampani, Y. Li, X. Jia, D. Lagun, F. Durand, W. T. Freeman, M. Matthews
Computer Vision and Pattern Recognition, CVPR’24 (oral)
P. Phongthawee, W. Chinchuthakun, N. Sinsunthithet, A. Raj, V. Jampani, P. Khungurn, S. Suwajanakorn
Computer Vision and Pattern Recognition, CVPR’24 (oral)
H. Hu, Z. Zhou, V. Jampani, S. Tulsiani
Computer Vision and Pattern Recognition, CVPR’24
L. Qi, L. Yang, W. Guo, Y. Xu, B. Du, V. Jampani, M. H. Yang
Computer Vision and Pattern Recognition, CVPR’24
Z. Huang, S. Stojanov, A. Thai, V. Jampani, J. M. Rehg
Computer Vision and Pattern Recognition, CVPR’24
J. Zhang, C. Herrmann, J. Hur, E. Chen, V. Jampani, D. Sun, M. H. Yang
Computer Vision and Pattern Recognition, CVPR’24
E Weber, A Holynski, V Jampani, S Saxena, N Snavely, A Kar, A. Kanazawa
Computer Vision and Pattern Recognition, CVPR’24
N. Ruiz, Y. Li, V. Jampani, W.Wei, T. Hou, Y. Pritch, N. Wadhwa, M. Rubinstein, K. Aberman
Computer Vision and Pattern Recognition, CVPR’24
Y. Xie, V. Jampani, L. Zhong, D. Sun, H. Jiang
International Conference on Learning Representations, ICLR’24
Z. Zhu, J. Wang, Y. Qin, D. Sun, V. Jampani, X. Wang
International Conference on 3D Vision, 3DV’24 (oral)
V. Jampani*, K. K. Maninis*, A. Engelhardt, A. Karpur, K. Truong, K. Sargent, S. Popov, A. Araujo, R. M. Brualla, K. Patel, D. Vlasic, V. Ferrari, A. Makadia, C. Liu, Y. Li, H. Zhou (*equal contribution)
Neural Information Processing Systems, NeurIPS’23
C-H. Yao, A. Raj, W-C. Hung, Y. Li, M. Rubinstein, M-H. Yang, V. Jampani
Neural Information Processing Systems, NeurIPS’23
W. Feng*, W. Zhu*, T-J. Fu, V. Jampani, A. Akula, X. He, S. Basu, X. E. Wang, W. Y. Wang (*equal contribution)
Neural Information Processing Systems, NeurIPS’23
J. Zhang, C. Herrmann, J. Hur, L. P. Cabrera, V. Jampani, D. Sun, M-H. Yang
Neural Information Processing Systems, NeurIPS’23
A. Raj, S. Kaza, B. Poole, M. Niemeyer, N. Ruiz, B. Mildenhall, S. Zada, K. Aberman, M. Rubinstein, J. Barron, Y, Li, V. Jampani
International Conference on Computer Vision, ICCV’23
pdf / project page / video
K. Gupta, V. Jampani, C. Esteves, A. Shrivastava, A. Makadia, N. Snavely, A. Kar
International Conference on Computer Vision, ICCV’23
pdf / project page / video
Z. Cheng, C. Esteves, V. Jampani, A. Kar, S. Maji, A. Makadia
International Conference on Computer Vision, ICCV’23
A. Akula, B. Driscoll, P. Narayana, S. Changpinyo, Z. Jia, S. Damle, G. Pruthi, S. Basu, L. Guibas, W. T. Freeman, Y. Li, V. Jampani
Computer Vision and Pattern Recognition, CVPR’23
pdf / project page / video
C-H. Yao, W-C. Hung, Y. Li, M. Rubinstein, M-H. Yang, V. Jampani
Computer Vision and Pattern Recognition, CVPR’23
pdf / project page / video / code (github)
G. Li, V. Jampani, D. Sun, L. Sevilla-Lara
Computer Vision and Pattern Recognition, CVPR’23
pdf / project page / video / code (github)
N. Ruiz, Y. Li, V. Jampani, Y. Pritch, M. Rubinstein, K. Aberman (oral, best student paper honorable mention)
Computer Vision and Pattern Recognition, CVPR’23
Z. Huang, V. Jampani, N. A. Thai, Y. Li, S. Stojanov, J. M. Rehg
Computer Vision and Pattern Recognition, CVPR’23
pdf / project page / video / code (github)
H. Rangwani, L. Bansal, K. Sharma, T. Karmali, V. Jampani, R. V. Babu
Computer Vision and Pattern Recognition, CVPR’23
W. Feng, X. He, T. J. Fu, V. Jampani, A. Akula, P. Narayana, S. Basu, X. E. Wang, W. Y. Wang
International Conference on Learning Representations, ICLR’23
C-H. Yao, W-C. Hung, Y. Li, M. Rubinstein, M-H. Yang, V. Jampani
Neural Information Processing Systems, NeurIPS’22
pdf / project page / video / code (github)
M. Boss, A. Engelhardt, A. Kar, Y. Li, D. Sun, J. Barron, H. Lensch, V. Jampani
Neural Information Processing Systems, NeurIPS’22
pdf / project page / video / code (github)
G. Yang, S. Benaim, V. Jampani, K. Genova, J. Barron, T. Funkhouser, B. Hariharan, S. Belongie
Neural Information Processing Systems, NeurIPS’22
J. N. Kundu*, S. Bhambri*, A. Kulkarni*, H. Sarkar, V. Jampani, R. V. Babu (*equal contribution)
Neural Information Processing Systems, NeurIPS’22
pdf / project page / video
X. He, D. Yang, W. Feng, T. J. Fu, A. Akula, V. Jampani, P. Narayana, S. Basu, W. Y. Wang, X. E. Wang
Empirical Methods in Natural Language Processing, EMNLP’22
R. Jasti, V. Jampani, D. Sun, M-H. Yang
International Conference on Image Processing, ICIP’22
Z. Huang, S. Stojanov, A. Thai, V. Jampani, J. M. Rehg
European Conference on Computer Vision, ECCV’22
H. Rangwani, N. Jaswani, T. Karmali, V. Jampani, R. V. Babu
European Conference on Computer Vision, ECCV’22
T. Karmali, R. Parihar, S. Agrawal, H. Rangwani, V. Jampani, M. Singh, R. V. Babu
European Conference on Computer Vision, ECCV’22
J. N. Kundu*, S. Bhambri*, A. Kulkarni*, H. Sarkar, V. Jampani, R. V. Babu (*equal contribution)
European Conference on Computer Vision, ECCV’22
pdf / project page / video / code (github)
J. N. Kundu*, A. Kulkarni*, S. Bhambri*, D. Mehta, S. Kulkarni, V. Jampani, R. V. Babu (*equal contribution)
International Conference on Machine Learning, ICML’22
pdf / project page / video / code (github)
K. A. Murphy, V. Jampani, S. Ramalingam, A. Makadia
Computer Vision and Pattern Recognition, CVPR’22
T. A. Habtegebrial, C. Gava, M. Rogge, D. Stricker, V. Jampani
Computer Vision and Pattern Recognition, CVPR’22
pdf / project page / video / code (github)
J. N. Kundu, S. Seth*, Y. Pradyumna*, V. Jampani, A. Chakraborty, R. V. Babu (*equal contribution)
Computer Vision and Pattern Recognition, CVPR’22
H. Song, D. Sun, S. Chun, V. Jampani, D. Han, B. Heo, W. Kim, M. H. Yang
International Conference on Learning Representations, ICLR’22
J. N. Kundu*, A. Kulkarni*, S. Bhambri*, V. Jampani, R. V. Babu (*equal contribution)
Association for the Advancement of Artificial Intelligence, AAAI’22
pdf / project page / video
T. Karmali*, A. Atrishi*, S. Harsha, S. Agrawal, V. Jampani, R. V. Babu (*equal contribution)
Winter Conference on Application of Computer Vision, WACV’22
pdf / project page / code (gdrive) / video
M. Boss, V. Jampani, R. Braun, C. Liu, J. T. Barron, H. Lensch
Neural Information Processing Systems, NeurIPS’21
pdf / project page / video / code (github)
G. Yang, D. Sun, V. Jampani, D. Vlasic, F. Cole, C. Liu, D. Ramanan
Neural Information Processing Systems, NeurIPS’21
A. Akula, V. Jampani, S. Changpinyo, S. C. Zhu
Neural Information Processing Systems, NeurIPS’21
M. Rakesh*, J. N. Kundu*, V. Jampani, R. V. Babu (*equal contribution)
Neural Information Processing Systems, NeurIPS’21
pdf / project page / video
J. N. Kundu, S. Seth, A. Jamkhandi, Y. Pradyumna, V. Jampani, R. V. Babu, A. Chakraborty
Neural Information Processing Systems, NeurIPS’21
V. Jampani*, H. Chang*, K. Sargent, A. Kar, R. Tucker, M. Krainin, D. Kaeser, W. T. Freeman, D. Salesin, B. Curless, C. Liu (*equal contribution)
International Conference on Computer Vision, ICCV’21 (oral)
pdf / project page / video / results
M. Boss, R. Braun, V. Jampani, J. T. Barron, C. Liu, H. Lensch
International Conference on Computer Vision, ICCV’21
pdf / project page / video / code (soon)
A. Liu*, R. Tucker*, V. Jampani, A. Makadia, N. Snavely, A. Kanazawa (*equal contribution)
International Conference on Computer Vision, ICCV’21 (oral)
pdf / project page / video / code (github)
C-H. Yao, W-C. Hung, V. Jampani, M-H. Yang
International Conference on Computer Vision, ICCV’21
pdf / project page / video / code (soon)
J. N. Kundu*, A. Kulkarni*, A. Singh, V. Jampani, R. V. Babu (*equal contribution)
International Conference on Computer Vision, ICCV’21
K. Murphy*, C. Esteves*, V. Jampani, S. Ramalingam, A. Makadia (*equal contribution)
International Conference on Machine Learning, ICML’21 (spotlight)
pdf / project page / video / code (github)
J. Zhou, V. Jampani, Z. Pi, Q. Liu, M-H. Yang.
Computer Vision and Pattern Recognition, CVPR’21
pdf / project page / video / code (github)
G. Yang, D. Sun, V. Jampani, D. Vlasic, F. Cole, H. Chang, D. Ramanan, W. T. Freeman, C. Liu
Computer Vision and Pattern Recognition, CVPR’21
D. Sun, D. Vlasic, C. Hermann, V. Jampani, M. Krainin, H. Chang, R. Zabih, W. T. Freeman, C. Liu
Computer Vision and Pattern Recognition, CVPR’21 (oral)
G. Li, V. Jampani, L. Sevilla-Lara, D.Sun, J. Kim, J. Kim
Computer Vision and Pattern Recognition, CVPR’21
pdf / project page / video / code (github)
T. A. Habtegebrial, V. Jampani, O. Gallo, D. Stricker
Neural Information Processing Systems, NeurIPS’20
pdf / video / project page / code (github)
J. N. Kundu*, M. Rakesh*, V. Jampani, R. M. Venkatesh, R. V. Babu (*equal contribution)
European Conference on Computer Vision, ECCV’20 (oral)
pdf / video / project page / code (github)
X. Li, S. Liu, K. Kim, S. D. Mello, V. Jampani, M. H. Yang and J. Kautz
European Conference on Computer Vision, ECCV’20
pdf / video / project page / code (github)
W. Yuan, B. Eckart, K. Kim, V. Jampani, D. Fox and J. Kautz
European Conference on Computer Vision, ECCV’20
pdf / video / project page / code (github)
S. K. Mustikovela, V. Jampani, S. D. Mello, S. Liu, U. Iqbal, C. Rother and J. Kautz
Computer Vision and Pattern Recognition, CVPR’20
pdf / video / project page / code (github)
M. Boss, V. Jampani, K. Kim, H. Lensch and J. Kautz
Computer Vision and Pattern Recognition, CVPR’20
pdf / video / project page / code (github)
J. N. Kundu*, S. Seth*, V. Jampani, M. Rakesh, R. V. Babu and A. Chakraborty (*equal contribution)
Computer Vision and Pattern Recognition, CVPR’20 (oral)
K. L. Navaneet, A. Mathew, S. Kashyap, W-C. Hung, V. Jampani and R. V. Babu
Computer Vision and Pattern Recognition, CVPR’20
S. Liu, X. Li, V. Jampani, S. D. Mello and J. Kautz
Internationl Conference on Computer Vision, ICCV’19
H. Jiang, D. Sun, V. Jampani, Z. Lv, E. Learned-Miller and J. Kautz
Internationl Conference on Computer Vision, ICCV’19 (oral)
T. Takikawa*, D. Akuna*, V. Jampani and S. Fidler (*equal contribution)
International Conference on Computer Vision, ICCV’19
pdf / code (github) / project page / video
H. Su, V. Jampani, D. Sun, O. Gallo, E. Learned-Miller and J. Kautz
Computer Vision and Pattern Recognition, CVPR’19
pdf / poster / video / project page / code (github)
W-C. Hung, V. Jampani, S. Liu, P. Molchanov, M-H. Yang and J. Kautz
Computer Vision and Pattern Recognition, CVPR’19
pdf / poster / video / project page / code (github)
A. Ranjan, V. Jampani, L. Balles, K. Kim, D. Sun, J. Wulff and M. J. Black
Computer Vision and Pattern Recognition, CVPR’19
K. L. Navaneet, P. Mandikal, V. Jampani and R. V. Babu
3D-WiDGET, CVPR-Workshops’19 (Oral)
V. Jampani, D. Sun, M-Y. Liu, M-H. Yang and J. Kautz
European Conference on Computer Vision, ECCV’18
pdf / poster / video / project page / code (github)
S. Liu, G. Zhong, S. D. Mello, J. Gu, V. Jampani, M-H. Yang and J. Kautz
European Conference on Computer Vision, ECCV’18
L. Sevilla, Y. Liao, F. Güney, V. Jampani, A. Geiger and M. J. Black
German Conference on Pattern Recognition, GCPR’18 (oral)
H. Su, V. Jampani, D. Sun, S. Maji, E. Kalogerakis, M-H. Yang and J. Kautz
Computer Vision and Pattern Recognition, CVPR’18 (oral, best paper honorable mention, NVAIL Pioneering Research Award)
pdf / poster / video / CVPR talk / code (github)
H. Jiang, D. Sun, V. Jampani, M-H. Yang, E. Learned-Miller and J. Kautz
Computer Vision and Pattern Recognition, CVPR’18 (spotlight)
pdf / supplementary / news / CVPR talk / video results
W-C. Tu, M-Y. Liu, V. Jampani, D. Sun, S-Y. Chien, M-H. Yang and J. Kautz
Computer Vision and Pattern Recognition, CVPR’18
J. Tremblay*, A. Prakash*, D. Acuna*, M. Brophy*, V. Jampani, C. Anil, T. To, E. Cameracci, S. Boochoon and S. Birchfield (*equal contribution)
Workshop on Autonomous Driving, CVPR-Workshops’18
R. Gadde, V. Jampani and P. V. Gehler
International Conference on Computer Vision, ICCV’17 (oral)
pdf / video / code (github) / ICCV talk / poster
V. Jampani, R. Gadde and P. V. Gehler
Computer Vision and Pattern Recognition, CVPR’17
pdf / supplementary / project page / code (github) / poster
R. Gadde*, V. Jampani*, R. Marlet and P. V. Gehler (*equal contribution)
Pattern Analysis and Machine Intelligence, PAMI’17
R. Gadde*, V. Jampani*, M. Kiefel, D. Kappler and P. V. Gehler (*equal contribution)
European Conference on Computer Vision, ECCV’16
pdf / supplementary / project page / code (github) / poster
V. Jampani, M. Kiefel and P. V. Gehler
Computer Vision and Pattern Recognition, CVPR’16
pdf / supplementary / project page / code (github) / poster
L. Sevilla, D. Sun, V. Jampani and M. J. Black
Computer Vision and Pattern Recognition, CVPR’16
pdf / video / project page / code (zip)
M. Kiefel, V. Jampani and P. V. Gehler
International Conference on Learning Representations, ICLR Workshops’15
V. Jampani*, S. M. A. Eslami*, D. Tarlow, P. Kohli and J. Winn (*equal contribution)
Artificial Intelligence and Statistics, AISTATS’15
pdf / supplementary / arXiv
V. Jampani*, R. Gadde* and P. V. Gehler (*equal contribution)
Winter Conference on Applications of Computer Vision, WACV’15
V. Jampani, V. Vaidya, J. Sivaswamy and K. L. Tourani
SPIE, Medical Imaging’11
V. Jampani, G. Ramos and S. Drucker
Microsoft Research Technial Report, Redmond, MSR-TR-2010-148
Theses
Learning based techniques for better inference in several computer vision models ranging from inverse graphics to freely parameterized neural networks.
V. Jampani
PhD Thesis, MPI for Intelligent Systems and University of Tübingen, December, 2016
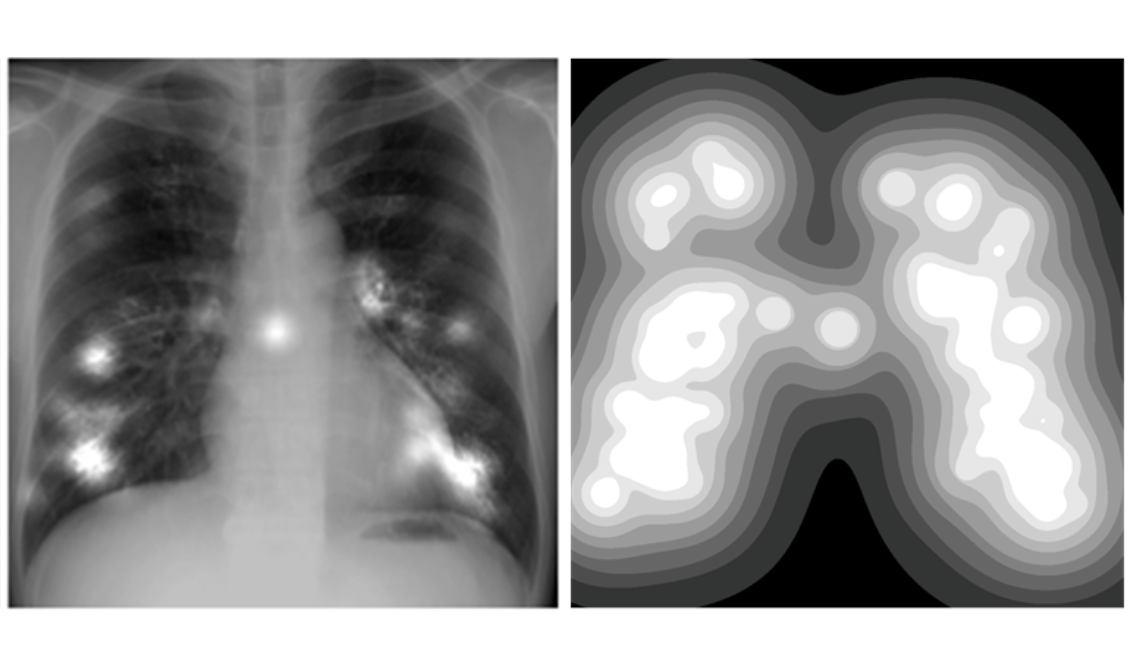
Eye tracking experimental studies and models for X-Ray Image Perception and Diagnosis.
V. Jampani
Master Thesis, IIIT-Hyderabad, January, 2013